하늘 아래 새로운 것은 없다. 단지 내가 발견하지 못했을 뿐이다.
산가지 숫자 표기법이 있다. 가느다란 막대를 일정하게 놓아 숫자를 표시하는 방법이다. 주판이 없었던 시절부터 쓰였고, 최소한 춘추전국시대, 약 2,500년 전부터 쓰였다고 짐작된다. 시장에서 거래를 하거나, 세금을 걷거나, 수 관련된 정보를 취합할 때 간단하게 이용할 수 있는 계산법으로 여겨진다. 산가지가 널리 쓰이던 시절에 이에 능한 사람은 곧 셈에 능한 것이고 명석한 사람으로 우대 받았다.
산가지로 숫자를 표시하는 방법은 단순하다. 10진법을 기본으로 한다. 자리수 마다 1~9까지의 숫자를 표시한다. 막대가 세로로 하나 있으면 1, 막대가 세로로 나란히 두개 있으면 2다. 5도 막대기 하나로 표시하되, 이는 가로로 놓는다. 6은 가로로 놓은 막대기 하나와 세로로 놓은 막대하나, 즉 직교하는 막대기 두 개로 표시한다. 큰 자리 수를 표시할 경우 중간에 숫자 0이 있다면 (예를 들어 101처럼) 그 자리를 적당히 비워 비어있는 숫자 0을 표시한다.
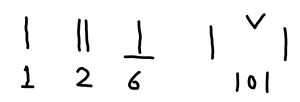
이해하기 쉬운 방법이지만 실제 셈을 하다보면 문제가 발생한다. 가장 큰 문제는 중간에 0이 두 개 있을 경우 하나 있을 때와 구분하기 어렵다. 예를 들어 606과 6006은 모두 6 사이를 적당히 띄워 표시해야 한다. 누구는 공간이 넉넉해 간격을 많이 띄울 수도 있다. 누구는 비교적 좁게 띄울 수도 있다. 사람마다 띄우는 간격이 달라 다른 사람이 표시한 숫자를 알 수가 없다. 또 하나의 문제는 1의 자리가 0일 경우 이를 표시하기 어렵다. 나는 60을 의도했지만 6이라고 읽는 사람들이 있다. 산가지 표식의 1의 자리 위치를 표시할 방법이 없다.
2,500년 전 사람들도 틀림없이 이런 문제를 겪었을 것이다. 그리고 그럴 듯한 해결책을 찾아냈다. 바로 자리수를 암시할 수 있는 추가 정보를 나뭇가지를 놓는 방법을 달리하여 표현해보는 것이다. 예를 들어 111을 표시한다면 첫 번째 1은 세로로, 두 번째 1은 가로로, 세 번째 1은 다시 세로로 놓는다. 일의 자리수를 놓을 때 세로로 놓는다는 점을 정해 놓으면 그 다음부터 십의 자리, 백의 자리를 놓을 때 이 규칙에 맞게 가로 세로를 변경하면 혼동될 일이 없다. 101 과, 1001의 구분도 가능하다. 나뭇가지 두 개가 가운데 간격을 두고 모두 세로로 놓여있다면 이것은 101이다. 만약 나뭇가지 두 개가 가운데 간격을 두고 첫 번째 것은 가로, 두 번째 것은 세로로 놓여있다면 이 것은 1001일 가능성이 크다. 100001를 표현한 것일 수도 있으나 산가지로 이 정도 큰 수를 표시할 일은 극히 드물었으리라 생각한다.
수는 기호와 상대적 위치로 정보를 표시한다. 현대는 인도-아라비아 숫자로 여겨지는 0부터 9까지 기호를 주로 이용한다. 산가지로 0을 표현할 수 있었다면 위 문제는 훨씬 간단히 해결했을 것이다. 하지만 추상적인 수에 대한 고려가 없이, 세상 사물을 세아리는 (Counting) 목적으로만 수를 쓴다면, 0을 표현하는 기호를 고안하는 것이 간단치 않았을 것이다. 따라서 숫자 ‘0’의 발명과 이용은 단순히 9개의 숫자에서 하나를 더 한 것 이상 의미를 지닌다. 세상에 존재하는 수에서 세상에 존재하지 않는 수로의 거대한 도약이다. 유리수에서 무리수의 발견, 무리수에서 허수의 발견 등 현대 수학에 도달하기 위한 몇 차례의 도약이 있었다.
이야기가 잠시 딴 길로 빠졌다. 산가지를 다르게 놓는 것으로 자리수를 표현 하는 것, 비록 두 가지 방법으로 절대적 위치가 아닌 왼쪽, 오른쪽 숫자와의 상대적 위치를 표현하는 이 것이, 포지션 인코딩(Position Encoding)이다. 풀어 쓰면 자리 수에 대한 추가 정보를 남겨 놓는 것이다. 따라서 이 수를 읽는 사람이 혼돈되지 않도록, 숫자 전체를 보지 않고도 숫자 하나만을 봐도 이 것이 어느 자리에 위치 하는지 알게한다. 이는 사람 뿐 아니라 컴퓨터에게도 마찬가지다.
거대한 도약을 거쳐 이 아이디어는 현대의 ChatGPT 와 같은 생성형 AI(Generative AI) 언어모델의 위치 정보 표시로 발전한다. ChatGPT와 같은 AI는 글을 어떻게 읽을까? 하나의 단락을 읽는다고 가정하자. ChatGPT는 사람과는 다른 독특한 끊어읽기 패턴이 있다. 글자가 아닌 Token이라는 단위로 읽는다. 주어지는 Token을 순서대로 읽어나가는 것은 사람과 다르지 않다. 다만 ChatGPT에게는 Token의 위치 정보를 함께 제공한다. 위 산가지 예에서 산가지를 놓는 방식으로 아주 미약한 추가정보 (홀수 위치 자리수 인지, 짝수 위치 자리수 인지를 표시하는 1bit 정보)를 함께 제공하는 것과 달리, ChatGPT에게는 현재 읽는 문맥이 시작점으로 부터 몇 번째 정보 인지를 가늠할 수 있는 정보를 추가로 준다. 따라서 같은 토큰이라도 문맥의 첫 번째 나온 것과 중간에 나온 것은 다른 값을 가진다. 만약 이러한 정보가 없다면, 굉장히 긴 문맥을 이해하고 답변해야 하는 일을 수행하지 못하고 항상 지엽적인 정보만을 이용해서 답변하는 경향이 강하게 될 것이다.
모두를 놀라게한 ChatGPT 일지라도 그 뒤에서 돌아가는 신경망의 구조는 완전히 새로운 것이 아니다. 세상에 이미 존재하는 것의 더 넓고, 더 깊은 복잡한 모델링으로 이루어진다. ‘기호(symbol)로 이루어진 순열(sequence) 내에서 각 기호의 위치를 알 수 있도록 한다’라는 매우 단순한 원칙이 산가지를 놓는 방법이나, 생성형 AI를 위한 입력 임베딩을 구성할 때 동일하게 적용된다. 생성형 AI 적용 이후에도 이 방법은 계속, 빠른 속도로 개선, 진화하고 있다. 아주 긴 시퀀스라도 그 위치 정보를 간결하고 중복되지 않도록 모델링, 저장토록 진화하고 있다.
ChatGPT의 학습이나 추론 과정도 뇌 속에서 일어나는 신경 전달 물질이 유발하는 전기 자극의 모델링이다. 그리고 반드시 더 복잡하고 최신의 것이 더 나은 것은 아니다. 단순한 것은 단순한 나름의 쓰임이 있으며, 복잡하고 어려운 것은 목적에 맞는 쓰임이 있다. 현대 과학과 기술의 발전으로 복잡하고 어려웠던 것 대안이 더 쉽고, 또 사용 가능하도록 바뀐 것이다.
길게 보면 문제도 반복되고, 해결 방법도 반복된다. 이 것은 우리의 인식, 사고, 감정은 쉽게 바뀌지 않기 때문이다. 인간이라는 종으로 규정되는 개체 내에서 세상과 소통한다는 근본적인 제약은 요즘말로 종족 특성, ‘종특’인 것이다. 따라서 복잡해보이는 현상과 문제도 인간이라는 개체와 그 환경으로 환원해서 살펴보면 문제와 해결이 몇 가지 유형으로 줄어드는 것이다. 향후에도 이 자리수 표기법은 빠르게 발전할 것이다. 이미 수권 분량의 문서를 ChatGPT에 줄때 효율적으로 위치 정보를 입력하는 방법이 고안되고 있다. 이 것은 0이 몇 개 있을 지 고민하고 산가지를 다른 방향으로 놓아 해결한다는, 1bit의 정보를 추가하겠다는 누군가의 2,500년 전 아이디어에서 출발한 것이다.